echo "Hello world"Hello worldWe are going to use Unix to create and prepare a directory for a data analysis project.
In general you want to name your files in a way that is related to their contents and specifies how they relate to other files. The Smithsonian Data Management Best Practices has “five precepts of file naming and organization” and they are:
- Have a distinctive, human-readable name that gives an indication of the content.
- Follow a consistent pattern that is machine-friendly.
- Organize files into directories (when necessary) that follow a consistent pattern.
- Avoid repetition of semantic elements among file and directory names.
- Have a file extension that matches the file format (no changing extensions!)
For specific recommendations we highly recommend you follow The Tidyverse Style Guide1.
echo "Hello world"Hello world


The structure on Windows looks something like this:
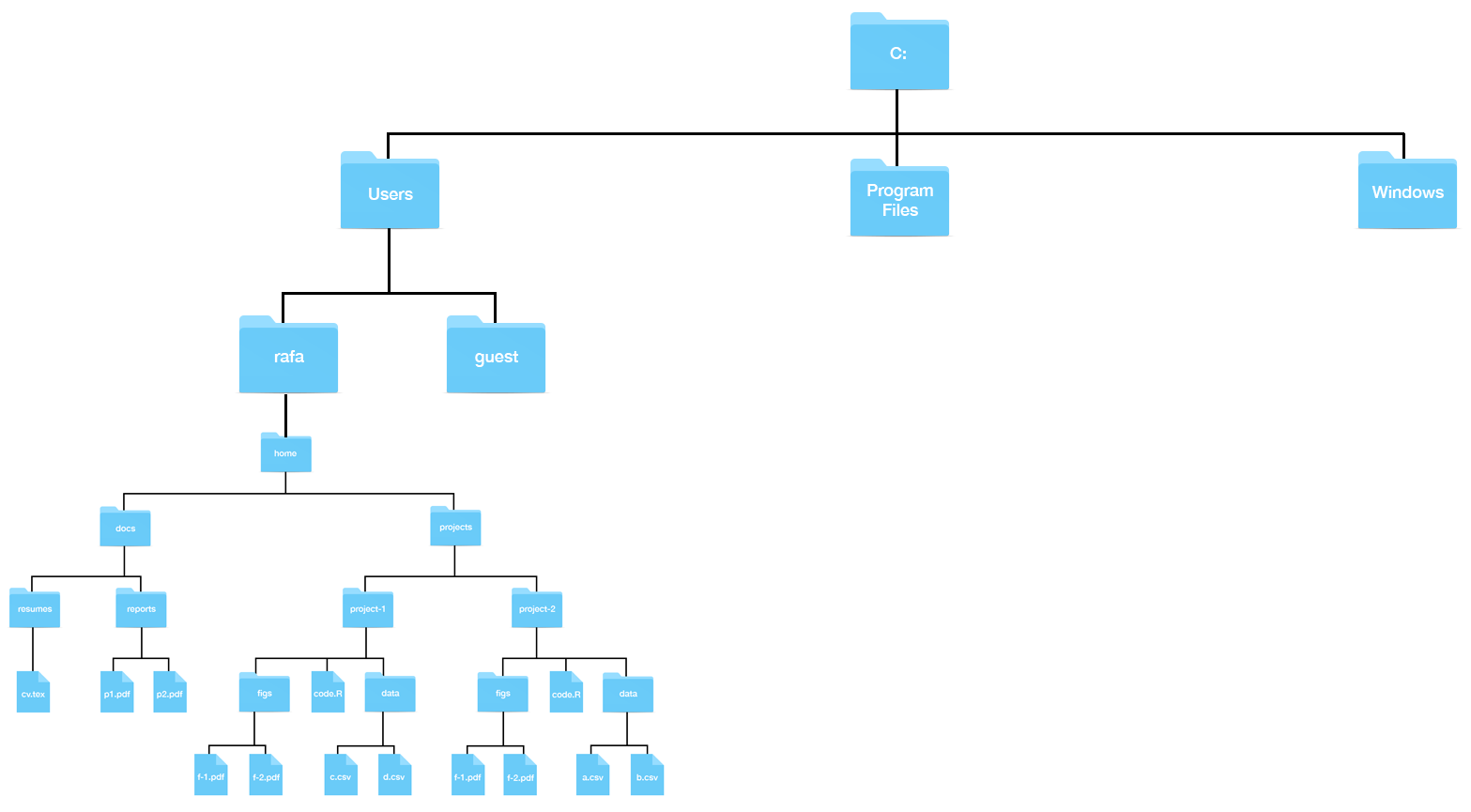
And on MacOS something like this:
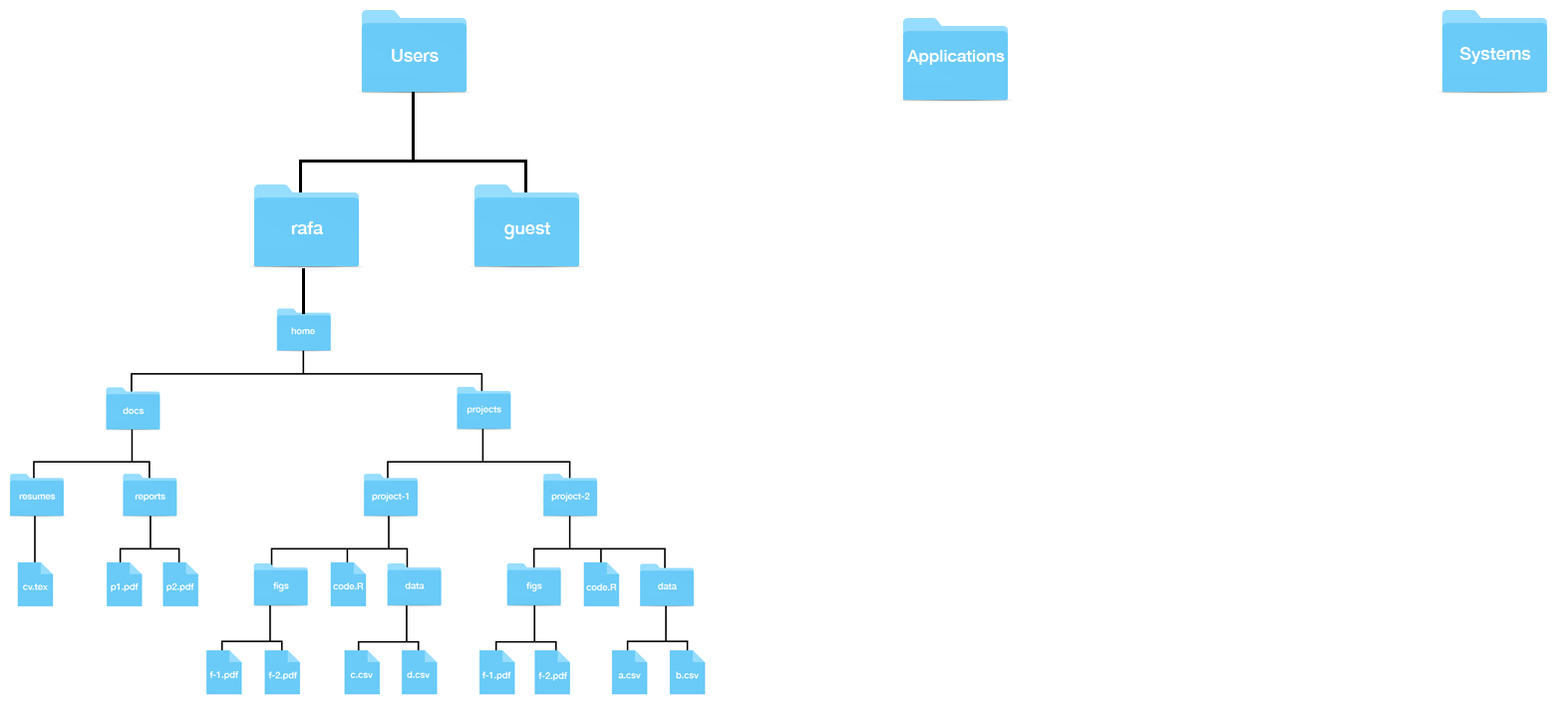
The working directory is the directly you are currently in. Later we will see that we can move to other directories using the command line. It’s similar to clicking on folders.
You can see your working directory like this:
pwd/Users/rafa/Documents/teaching/bst260/2023In R we can use
getwd()[1] "/Users/rafa/Documents/teaching/bst260/2023"This string returned in previous command is full path to working directory.
The full path to your home directory is stored in an environment variable, discussed in more detail later:
echo $HOME/Users/rafaIn Unix, we use the shorthand ~ as a nickname for your home directory
Example: the full path for docs (in image above) can be written like this ~/docs.
Most terminals will show the path to your working directory right on the command line.
Exercise: Open a terminal window and see if the working directory is listed.
ls: Listing directory content
lsmkdir and rmdir: make and remove a directorymkdir projectsIf you do this correctly, nothing will happen: no news is good news. If the directory already exists, you will get an error message and the existing directory will remain untouched.
To confirm that you created these directories, you can list the directories:
lsYou should see the directories we just created listed.
mkdir docs teachingIf you made a mistake and need to remove the directory, you can use the command rmdir to remove it.
mkdir junk
rmdir junkIn Unix you can auto-complete by hitting tab. This means that we can type cd d then hit tab. Unix will either auto-complete if docs is the only directory/file starting with d or show you the options. Try it out! Using Unix without auto-complete will make it unbearable.
cd continuedGoing back one:
cd ..Going home:
cd ~or simply:
cdStating put (later we see why useful)
cd .Going far:
cd /c/Users/yourusername/projectsUsing relative paths:
cd ../..Going to previous working directory
cd -Let’s explore some examples of navigating a filesystem using the command-line. Download and expand this file into a temporary directory and you will have the data struct in the following image.

~/projects, move to figs in project-1.cd project-1/figs~/projects. Move to reports in docs in two different ways:This is a relative path:
cd ../docs/reportsThe full path:
cd ~/docs/reports ## assuming ~ is hometo~/projects/project-1/figs and want to change to ~/projects/project-2, show two different ways, one with relative path and one with full path.This is with relative path
cd ../../projects-2With a full path
cd ~/projects/proejcts-2 ## assuming home is ~mv: moving filesmv path-to-file path-to-destination-directoryFor example, if we want to move the file cv.tex from resumes to reports, you could use the full paths like this:
mv ~/docs/resumes/cv.tex ~/docs/reports/You can also use relative paths. So you could do this:
cd ~/docs/resumes
mv cv.tex ../reports/or this:
cd ~/docs/reports/
mv ../resumes/cv.tex ./We can also use mv to change the name of a file.
cd ~/docs/resumes
mv cv.tex resume.texWe can also combine the move and a rename. For example:
cd ~/docs/resumes
mv cv.tex ../reports/resume.texAnd we can move entire directories. To move the resumes directory into reports, we do as follows:
mv ~/docs/resumes ~/docs/reports/It is important to add the last / to make it clear you do not want to rename the resumes directory to reports, but rather move it into the reports directory.
cp: copying filesThe command cp behaves similar to mv except instead of moving, we copy the file, meaning that the original file stays untouched.
rm: removing filesIn point-and-click systems, we remove files by dragging and dropping them into the trash or using a special click on the mouse. In Unix, we use the rm command.
Unlike throwing files into the trash, rm is permanent. Be careful!
The general way it works is as follows:
rm filenameYou can actually list files as well like this:
rm filename-1 filename-2 filename-3You can use full or relative paths. To remove directories, you will have to learn about arguments, which we do later.
less: looking at a fileOften you want to quickly look at the content of a file. If this file is a text file, the quickest way to do is by using the command less. To look a the file cv.tex, you do this:
cd ~/docs/resumes
less cv.tex To exit the viewer, you type q. If the files are long, you can use the arrow keys to move up and down. There are many other keyboard commands you can use within less to, for example, search or jump pages.
We are now ready to prepare a directory for a project. We will use the US murders project2 as an example.
You should start by creating a directory where you will keep all your projects. We recommend a directory called projects in your home directory. To do this you would type:
cd ~
mkdir projectsOur project relates to gun violence murders so we will call the directory for our project murders. It will be a subdirectory in our projects directories. In the murders directory, we will create two subdirectories to hold the raw data and intermediate data. We will call these data and rda, respectively.
Open a terminal and make sure you are in the home directory:
cd ~Now run the following commands to create the directory structure we want. At the end, we use ls and pwd to confirm we have generated the correct directories in the correct working directory:
cd projects
mkdir murders
cd murders
mkdir data rdas
ls
pwdNote that the full path of our murders dataset is ~/projects/murders.
So if we open a new terminal and want to navigate into that directory we type:
cd projects/murdersIn the course we will be using RStudio to edit files. But there will be situations in where this is not the most efficient approach. You might also need to write R code on a server that does not have RStudio installed. For this reason you need to learn to use a command-line text editors or terminal-based text editors. A key feature of these is that you can do everything you need on a terminal without the need for graphical interface. This is often necessary when using remote servers or computers you are not sitting in front off.
Command-line text editors are essential tools, especially for system administrators, developers, and other users who frequently work in a terminal environment. Here are some of the most popular command-line text editors:
Nano - Easy to use and beginner-friendly.
Pico - Originally part of the Pine email client (Pico = PIne COmposer). It’s a simple editor and was widely used before Nano came around.
Vi or Vim - Vi is one of the oldest text editors and comes pre-installed on many UNIX systems. It is harder to use than Nano and Pico but is much more powerful. Vim is an enhanced version of Vi.
Emacs - Another old and powerful text editor. It’s known for being extremely extensible.
To use these to edit a file you type, for example,
nano filenamerm -r directory-nameall files, subdirectories, files in subdirectories, subdirectories in subdirectories, and so on, will be removed. This is equivalent to throwing a folder in the trash, except you can’t recover it. Once you remove it, it is deleted for good. Often, when you are removing directories, you will encounter files that are protected. In such cases, you can use the argument -f which stands for force.
You can also combine arguments. For instance, to remove a directory regardless of protected files, you type:
rm -rf directory-nameRemember that once you remove there is no going back, so use this command very carefully.
A command that is often called with argument is ls. Here are some examples:
ls -a ls -l It is often useful to see files in chronological order. For that we use:
ls -t and to reverse the order of how files are shown you can use:
ls -r We can combine all these arguments to show more information for all files in reverse chronological order:
ls -lart Each command has a different set of arguments. In the next section, we learn how to find out what they each do.
man lsor
ls --helpman ls | lessor in Git Bash:
ls --help | less This is also useful when listing files with many files. We can type:
ls -lart | less ls *.htmlTo remove all html files in a directory, we would type:
rm *.htmlThe other useful wild card is the ? symbol.
rm file-???.htmlThis will only remove files with that format.
We can combine wild cards. For example, to remove all files with the name file-001 regardless of suffix, we can type:
rm file-001.* Combining rm with the * wild card can be dangerous. There are combinations of these commands that will erase your entire filesystem without asking “are you sure?”. Make sure you understand how it works before using this wild card with the rm command.**
Earlier we saw this:
echo $HOME You can see them all by typing:
envYou can change some of these environment variables. But their names vary across different shells. We describe shells in the next section.
echo $SHELLThe most common one is bash.
Once you know the shell, you can change environmental variables. In Bash Shell, we do it using export variable value. To change the path, described in more detail soon, type: (Don’t actually run this command though!)
export PATH = /usr/bin/
which gitThat directory is probably full of program files. The directory /usr/bin usually holds many program files. If you type:
ls /usr/binin your terminal, you will see several executable files.
There are other directories that usually hold program files. The Application directory in the Mac or Program Files directory in Windows are examples.
To see where your system looks:
echo $PATHyou will see a list of directories separated by :. The directory /usr/bin is probably one of the first ones on the list.
If your command is called my-ls, you can type:
./my-lsOnce you have mastered the basics of Unix, you should consider learning to write your own executables as they can help alleviate repetitive work.
If you type:
ls -lAt the beginning, you will see a series of symbols like this -rw-r--r--. This string indicates the type of file: regular file -, directory d, or executable x. This string also indicates the permission of the file: is it readable? writable? executable? Can other users on the system read the file? Can other users on the system edit the file? Can other users execute if the file is executable? This is more advanced than what we cover here, but you can learn much more in a Unix reference book.
curl - download data from the internet.
tar - archive files and subdirectories of a directory into one file.
ssh - connect to another computer.
find - search for files by filename in your system.
grep - search for patterns in a file.
awk/sed - These are two very powerful commands that permit you to find specific strings in files and change them.
ln - create a symbolic link. We do not recommend its use, but you should be familiar with it.
To get started.
You are not allowed to use RStudio or point and click for any of the exercises below. Open a text file called commands.txt using a text editor and keep a log of the commands you use in the exercises below. If you want to take notes, you can use # to distinguish notes from commands.
Decide on a directory where you will save your class materials. Navigate into the directory using a full path.
Make a directory called project-1 and cd into that directory.
Make directors called data: data, rdas, code, and docs.
Use curl or wget to download the file https://raw.githubusercontent.com/rafalab/dslabs/master/inst/extdata/murders.csv and store it in rdas.
Create a R file in the code directory called code-1.R, write the following code in the file so that if the working directory is code it reads in the csv file you just downloaded. Use only relative paths.
filename <- ""
dat <- read.csv(filename)rdas directory. Use only relative paths.out <- ""
dat <- save(dat, file = out)code-2.R in the code directory. Use the following command to add a line to the file.echo "load('../rdas/murders.rda')" > code/code-2.RCheck to see if the line of code as added without opening a text editor.
Navigate to the code directory and list all the files ending in .R.
Navigate to the project-1 directory. Without navigating away, change the name of code-1.R to import.R, but keep the file in the same directory.
Change the name of the project directory to murders. Describe what you have to change so the R script sill does the right thing and how this would be different if you had used full paths.
Bonus : Navigate to the murders directory. Read the man page for the find function. Use find to list all the files ending in .R.